
Database Schema automatically creates an accessible default once you establish a database. Multiple schemas can exist in a single database. The namespace is one way to look at the schema. The identical Table, index, view, etc., can exist in many schemas.
Table of Contents
- Postgres system architecture & its most basic form
- Client-side apps that access databases are known as front-end apps. Applications for clients can vary significantly:
- Tablespace
- Database table framework
- Client-side apps that access databases are known as front-end apps. Applications for clients can vary significantly:
- When getting information out of a database, there are two main ways to do it:
- Using sequential scanning as well as B-tree index scanning
- Scanned index files from B-trees including index tuple structures
- System tables
- Key operations in the system table
- SQL query execution in a PostgreSQL database
- Potgres, the resident process
- Postgres (first run)
- Additional procedures
- Postmaster’s primary procedure and service procedure
- Writers Procedure
- Routinely running checkpoints
- bgwriter error
- max pages for bgwriter LRU
- Conclusion
Table of Contents
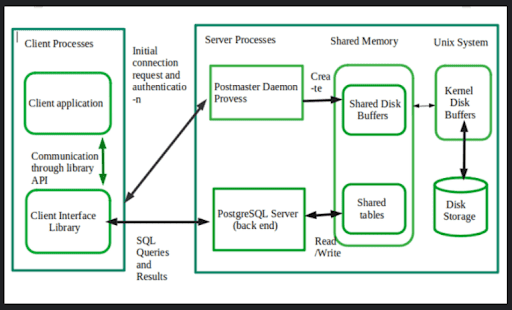
Postgres system architecture in its most basic form:
PostgreSQL’s service delivery is based across the client/server (C/S) paradigm. The following interconnected applications make up PostgreSQL sessions:
-
A server running procedure
This procedure handles the client’s database operations, verifies the connection that the client makes to the database, as well as maintains the database folders. This step is known as Postgres in the programme.
-
Client-side apps that access databases are known as front-end apps. Applications for clients can vary significantly:
They can take the form of an antagonist interface tool, an app with a graphical user interface, an internet server that pulls web pages from a database, or even a specialised tool for managing databases. While the latest version of PostgreSQL does provide several client apps, the vast majority of these are user-built.
The client as well as server, as in a standard C/S application, may exist on separate hosts. They are currently communicating across TCP/IP; bear that in consideration since the database server system might not have the same file available on the client, or may require an alternate filename in order to access it.
The PostgreSQL server can process numerous customer demands at once. To get around this, it will create a new process for every request (sometimes called a “fork”) so that both the client and the server processes will communicate with each other directly instead of using the original Postgres session. Thus, the server-side main process has been operating in the background, awaiting the client to establish a connection; the client, as well as its corresponding server-side processes, will only execute when necessary. PostgreSQL Training developers play an important role in this process.
-
Tablespace
To hold all of the database items, PostgreSQL uses its largest conceptual storage unit, a table space. In order to avoid using it by default, you have the option to define the tablespace of a database object when establishing it.
-
Database table framework
The page refers to the block in disc storage and Buffers to the unit in RAM in postgresql. The relation is the name for tables as well as indexes, as well as Tuple is the name for rows. Data entry and analysis isPage default size is 8 KB, the smallest bit. The size defines the BLCKSZsize passed to Pageby during Postgresql compilation. The pages that make up a table file are BLCKSZbytes in size, so there are many Tuples on every page. Raising the size of BLCKSZ properly can marginally enhance database performance for hardware that has excellent I/O performance as well as databases that are analysis-based. Top easiest tech skills to learn.
-
Using sequential scanning as well as B-tree index scanning
By iteratively scanning all line references on each page, serial scanning reads every tuple on every page.
-
Scanned index files from B-trees include index tuple structures
The index key with the TID indicates which heap trio to use to make up every tuple.
Schematic of the PostgreSQL database, showing its components and their relationships:
- Each of PostgreSQL’s five components—the system table, network management, compilation operation, storage management, as well as transaction management—work together to form the database.
- The link management system acts as the control logic for the system, receives operation demands from outside sources, and handles and disperses them.
- Finalising the analysis, manufacturing, and translation of the operation demands in the database, the creation of the execution system’s query executors as well as query compiler makes it possible to operate on data stored on physical media;
- An index manager, a memory director, as well as a third-party memory manager make up the storage management system. Its functions include supporting the creation of a query system as well as keeping and handling physical data.
The four main components of the transaction systems are the lock manager, concurrent control, transactions manager, as well as log manager. Together, the transaction management as well as log manager finish off the support for operation requests’ compliance with transactions.
-
System tables
The data dictionary function is essential for relational databases to enable database system control. For system administration, the data dictionaries not only keep object descriptions but also object details. The dictionary of data is a repository for all metadata about objects, including their characteristics, that is stored in the database system. It also includes details on the relationships among objects, the organic meaning of those attributes, and the history of revisions to the data dictionary. Management, as well as control information for systems with relational databases, revolve around the data dictionary. System tables are like data dictionaries in a database.
The PostgreSQL database keeps architectural metadata in the system table. Users can delete or rebuild it so that PostgreSQL shows it as a shared table or view that contains system data.
Whenever the system is operational, there is heavy traffic to the system table because it contains all of the database’s information. We have improved system performance by creating shared systems tables in RAM and by using hash tables to boost query efficiency.
Critical operations in the system table
- 1 pg_namespace namespace for storing
- 2 details on the pg_tablespace storage area
- In the current data collection cluster, 3 pg_database maintains details regarding the database.
- 4 pg_class documents data from database objects and tables with a common structure, such as TOAST tables, indexes, sequences, views, and composite data types.
- 5 pg_type is a data type store.
- The 6 pg_attribute table maintains the table’s attributes.
- 7 The pg_index variable contains data unique to the index.
The Postgres programme is where all the meat and potatoes of the PostgreSQL system of databases are. There it is, the primary method of the Main module. Starting the database server as well as initialising the data set are the two steps that will lead to its execution. Before passing over the command line inputs to the appropriate module, the Main module primarily checks the present operating system platform, sets as well as initialises environmental variables relating to the platform, and subsequently continues working.
SQL query execution in a PostgreSQL database
In response to user connect requests, the PostgreSQL server Postmaster launches a background Postgres service instance and, in addition, related background service procedures such as SysLogger, PgStat, as well as AutoVacuum.
The following is the initial setup for Postmaster as it joins the loop monitor:
- Background Writer, or BgWriter,
- WalWriter (the process of writing logs before writing),
- The prep-write log archive method or PgArch.
Postgres, the resident process
Postmaster is another name for the local procedure that controls the server side. As a default, it waits for the front end to handle connections by listening to ports 5432 on the UNIX Domain Socket as well as TCP/IP (Windows, etc.). In PostgreSQL’s configuration file, PostgreSQL.conf, you can alter the listening port address.
With the front end linked, PostgreSQL will use fork(2) to create a child process. You can create a fresh process using createProcess() if the Fork(2) Windows platform is not available. Here, you’ll need to make use of the shared memory in order to inherit the information of the parent process, as, in contrast to fork(2), this won’t happen automatically.
Postgres (first run)
Due to the security policy set in pg_hba.conf, the child process decides if to allow the connection. The policy states that it will not allow access from specific IP addresses or networks or that it may restrict access to specific people or databases.
After receiving requests from the front end, Postgres will get the database, return the outcomes, and occasionally update the database. The transaction log (also known as the WAL log in PostgreSQL) will additionally contain the modified data. For the most part, this comes in handy in the following scenarios: server downtime, power outage, and recovery procedure restart. We also archive a log so we can use it for recovery purposes. Database replica in real-time is possible after PostgreSQL 9.0 by moving WAL logs across PostgreSQL. A function known as “database replication” performs this task.
Additional procedures
Postgres isn’t the only database that uses auxiliary sessions. Resident Postgres initiated all of these procedures.
-
Postmaster’s primary procedure and service procedure
Starting the primary Postmaster procedure is the initial step in starting the PG database. This process initiates and terminates the database session; it is the master control procedure for the PG database. The following is an example of how the Postmaster process is really only a connection to the postgres command:
Run postgres from the command line in the /opt/postgresql/bin/postmaster directory.
Users are required to connect to the Postmaster processes before they may access the PG database. It is now the client’s turn to authenticate with the Postmaster main function. It is the message that determines how the Postmaster primary process is authorised. Once the verification is successful, the main procedure of Postmaster will split. For this user’s connection, we offer a session services process. Test=# select pid, username, client_addr, and client_port from pg_stat_activity; to display the service process pid in the pg_stat_activity table.
-
Writers Procedure
At the specified intervals, the Writer procedure copies data from the shared cache to the disc. By following this procedure, you can keep the server’s throughput from degrading due to a high volume of disc writes throughout checkpoint (checkpoint). Ever since it woke up, the previous writer had been residing in memory, yet it has been ineffective. After working for a while, it will go to sleep. In postgresql.conf, you’ll find the bgwriter_delay parameter, which specifies the sleep period. Two hundred milliseconds is the default.
-
Routinely running checkpoints
In order to ensure that the shared memory as well as database records are always up-to-date, the checkpoint writes the contents of the common memory cache to the database record. By doing so, you can stop WAL from growing infinitely and reduce the time it takes for the system to recover from crashes caused by WAL.
Time intervals for running checkpoints can be defined in postgresql.conf using the checkpoint_segments as well as checkpoint_timeout parameters.
One process that writes dirty webpages in shared memory to disc is the Writer process. It serves a dual purpose: first, it writes all dirty pages to disc during the normal checkpoint using the BgWriter; second, it periodically flushes out dirty information from the memory buffer and writes it to disc to minimise blocking throughout the query. Preparing some dirty pages ahead of time can decrease the number of input/output operations needed to set checkpoints (CheckPoint is a database recovery method), resulting in a more stable IO strain on the system. One of the new features introduced with PostgreSQL 8.0 is BgWriter. You can control its mechanism by setting options within the postgresql.conf file that begins with “bgwriter_”:
-
bgwriter error:
How long does it take for the background writer to process 2 consecutive flushes of data. The nanosecond value is 200 by default.
-
maxpages for bgwriter LRU:
Most data that the background writer processes can be written sequentially. One hundred buffer units is the average. The background writer function will finish the write operation in its entirety if the quantity of dirty data is below this value. On the other hand, the process on the server will complete the majority of the work if it is larger than this value. Setting this value to 0 disables the background writer as well as forces the server process to handle all dirty data writing; setting it to -1 reverses the order of operations.
Conclusion
PostgreSQL’s database server design depends on processes. It separates the system as well as user workers into their own operating system programs. To set up a PostgreSQL database, look for the file named “postgresql. conf” at your data directory’s base.